Parallellm Pump
By Luke Miller
- 10 minute read - 2094 wordsLarge Language Model (LLM) tools, such as ChatGPT and DeepSeek, have become a key part of people’s workflow, in professional and everyday usage. However, there are dozens of different providers now offering a myriad of options all at different price points; even a single provider has a multitude of models to choose from.
So where do you begin? The Parallellm Pump offers developers a power tool for making response comparisons, asynchronously, to let you be the judge of which provider returns the best result. Still not sure? You can even ask the LLMs themselves to make the decision for you!
One use case of Parallellm could be for fact-checking: we know that LLMs are liable to make1 many2 mistakes3 (including getting the meaning of NASA wrong - see Study: ChatGPT vs Claude). Having a tool where you can poll for several answers would give you confidence in their reliability - the chance of them all getting it wrong is unlikely.
Also, if you’re looking to generate content from a blank page (a story, tweet storm, email, etc.), having a way to see a variety of options quickly often helps you to discover how you wanted to express that idea.
This article will walk you through how to use the Parallellm Pump, and its various features, before diving into a mini-study of a selection of models’ performance on a bank of prompts. The study shows that ChatGPT and DeepSeek often out-perform Claude and Gemini; also we find that Claude often dislikes its own responses (although our prompt corpus does not have any software-engineering queries, arguably its forte).
Currently, this tool requires you to bring your own API key(s), which makes it predominantly a developer tool. In the future, I hope to release something for the wider audience - watch this space for updates 🗞️
Please do ⭐ the GitHub page if you’ve enjoyed reading this article.

Contents
Usage
The vanilla usage is simply to run pump.py to prompt multiple LLMs in parallel. This will initiate asynchronous calls
to two providers (in this case), as shown in the example below:
python -m src.pump --providers chatgpt claude --prompt "What is the significance of the number 42? Explain in 50 words max."
2025-01-28 15:57:17,903 INFO:Running the pump for the following providers: openai, anthropic
2025-01-28 15:57:19,884 INFO:HTTP Request: POST https://api.openai.com/v1/chat/completions "HTTP/1.1 200 OK"
2025-01-28 15:57:19,927 INFO:OpenAI response time: 1.96s
2025-01-28 15:57:20,103 INFO:HTTP Request: POST https://api.anthropic.com/v1/messages "HTTP/1.1 200 OK"
2025-01-28 15:57:20,134 INFO:Anthropic response time: 2.13s
2025-01-28 15:57:20,135 INFO:Total run time: 2.23s
2025-01-28 15:57:20,135 INFO:Results
chatgpt
_______
The number 42 is famously known as the 'Answer to the Ultimate Question of Life, the Universe, and Everything' in
Douglas Adams' science fiction series, "The Hitchhiker's Guide to the Galaxy." Its absurdity and humor symbolize
the complexity of existence, prompting philosophical reflection on the search for meaning.
claude
______
42 is famously the "Answer to the Ultimate Question of Life, the Universe, and Everything" in Douglas Adams'
"The Hitchhiker's Guide to the Galaxy." It\'s become a popular cultural reference symbolizing the search for
meaning, though in the book, the answer is deliberately meaningless.
Note that the total run time is reported - you can see that it took 2.23s to get responses from both models and process them, which is only a little longer than the slower of the two responses (Claude). This is a big benefit of using asyncio (see Technical Details).
A fun and useful extension is to use the prefer command to ask the models which one they think is the best. The same
principle of running in parallel applies here, too, except that we proceed in two stages: first the original prompt,
then second collect those responses to form a new prompt and ask all models which model they preferred (anonymously).
In the example shown below, both Claude and ChatGPT prefer Claude’s response. Sorry OpenAI. Ironically, Claude’s response is based somewhat on a miscalculation of the word count - ChatGPT does not exceed the 50-word limit. Claude cleverly uses exactly 42 words in its response though 🤯
python -m src.prefer --providers chatgpt claude --prompt "What is the significance of the number 42? Explain in 50 words max."
#... truncated output
2025-01-28 16:04:11,092 INFO:Total run time: 8.23s
2025-01-28 16:04:11,092 INFO:Final preference results:
chatgpt
_______
1. Response 2 (claude)
2. Response 1 (chatgpt)
- **Factuality**: Both responses accurately reference Douglas Adams' work, but Response 2 (claude) includes the cultural impact and significance of cosmic irony, providing a broader context.
- **Writing Style**: Response 2 (claude) is more concise and clear, adhering to the 50-word limit effectively without any additional explanation, whereas Response 1 (chatgpt) adds some unnecessary detail.
- **Clarity**: Response 2 (claude) presents the information in a straightforward manner, making it easier to understand the significance of the number 42 quickly.
claude
______
Rankings:
1. Response 2 (claude)
2. Response 1 (chatgpt)
Reasoning:
* Response 2 (claude) is more concise while maintaining all essential information
* Response 2 (claude) includes the clever additional detail about the question being unknown, which is an important part of the story's irony
* Response 1 (chatgpt) slightly exceeds the 50-word limit given in the prompt
* Both responses are factually accurate, but Response 2 (claude) delivers the information more efficiently and elegantly
* Response 2 (claude) better captures the essence of the reference while staying within the word limit constraint
The difference between the responses is subtle, but Response 2 (claude)'s adherence to the word limit while including a key detail about the unknown question makes it the superior answer.
Technical Details
Here is a high-level overview of the technical features of this project:
- It makes use of
asyncioto make sure you’re only waiting for the slowest model to finish. - Requires configuration of your own API keys for each LLM provider you want to use.
- Thin set of dependencies (mostly the vendor libraries for calling the LLMs).
- Very simple interface to run the pump.
Installation & Setup
Dependencies:
git clone git@github.com:lukerm/parallellm-pump.git
cd parallellm-pump
pip install -r requirements.txt
Configuration: make a JSON file to store your API keys, as shown below.
mkdir -p config/secret
cp config/api-keys-template.json config/secret/api-keys.json
# then edit the file to include your personal API keys
Please never commit your API keys to the repository! For this setup, there is a .gitignore entry to prevent this happening,
but please do take extra care on this step.
Study: Four Providers
We can use the prefer feature of the Parallellm Pump to run a statistical experiment which looks to rank the best responses
across a range of different prompts. To account for the variability in the generation process (responding and rating),
we run ten trials for each prompt.
Each LLM provider will respond to a prompt, then each one will rate all four responses given, ranking them from best (1) to worst (4). The responses are given anonymously, so that cheating or self-promotion is not possible. This procedure is run ten times for each of the ten sample prompts.
Taking a pure average of the responders’ ranks across the experiments, we see that ChatGPT and DeepSeek fare very well, each scoring an average of rank of close to 2 (lower is better), whereas Claude and Gemini lag behind scoring close to 3:
| Responder LLM | Mean Rank |
|---------------|-----------|
| ChatGPT | 1.92 |
| DeepSeek | 2.00 |
| Gemini | 2.92 |
| Claude | 3.15 |
Looking more closely, we can probe with top-N rank percentages, which check if the response is in the top 1 or 2 ranks, then average over the four raters and the independents repeats to stabilise the metrics (higher is better). There is an implicit assumption that each rater holds equal weight in the vote.
From the left-hand boxplot below, we see that DeepSeek is the top-rated responder about a third of the time (by median), and ChatGPT fares even better at nearly half the time at the top. Loosening the metric a little, the right-hand plot shows that both ChatGPT and DeepSeek attain a 1st or 2nd rank more than 75% of the time!
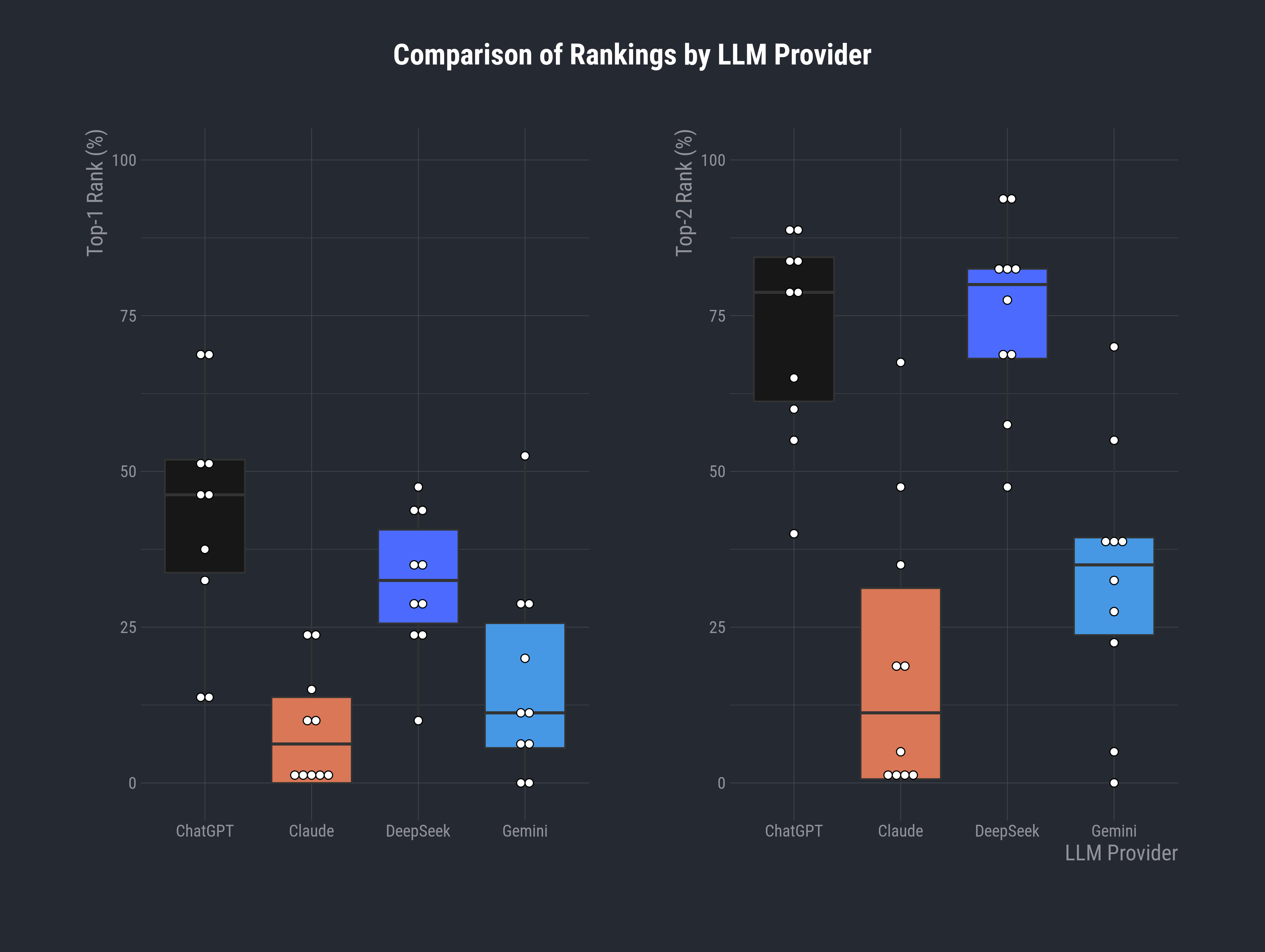
I will note that, whilst Claude is at the bottom of the pack by any metric you use, it may depend somewhat on the type of prompt. There is consensus that Claude performs very well on coding and software-engineering exercises45 which were not represented in my selection of prompts.
The heatmap of responder-rater pairs should reveal whether there are any particular biases of providers (dis)approving of certain styles. Ideally in the perfect agreement scenario, the heatmap would exhibit distinct rows each with their own colour. This is somewhat visible in the Claude row since everyone - including Claude - consistently ranks their responses poorly. In fact, Claude is apparently the most self-critical of its responses!
However, we do see certain hot spots where, for example, DeepSeek very often decides that it does not like Gemini’s responses. Also, we see that Claude, and Gemini to some extent, particularly dislikes ChatGPT’s responses more than the rest. This does beg the question of whether the equal-voting assumption is valid, and if ChatGPT would get even higher scores if, say, Claude were marginally down-weighted.
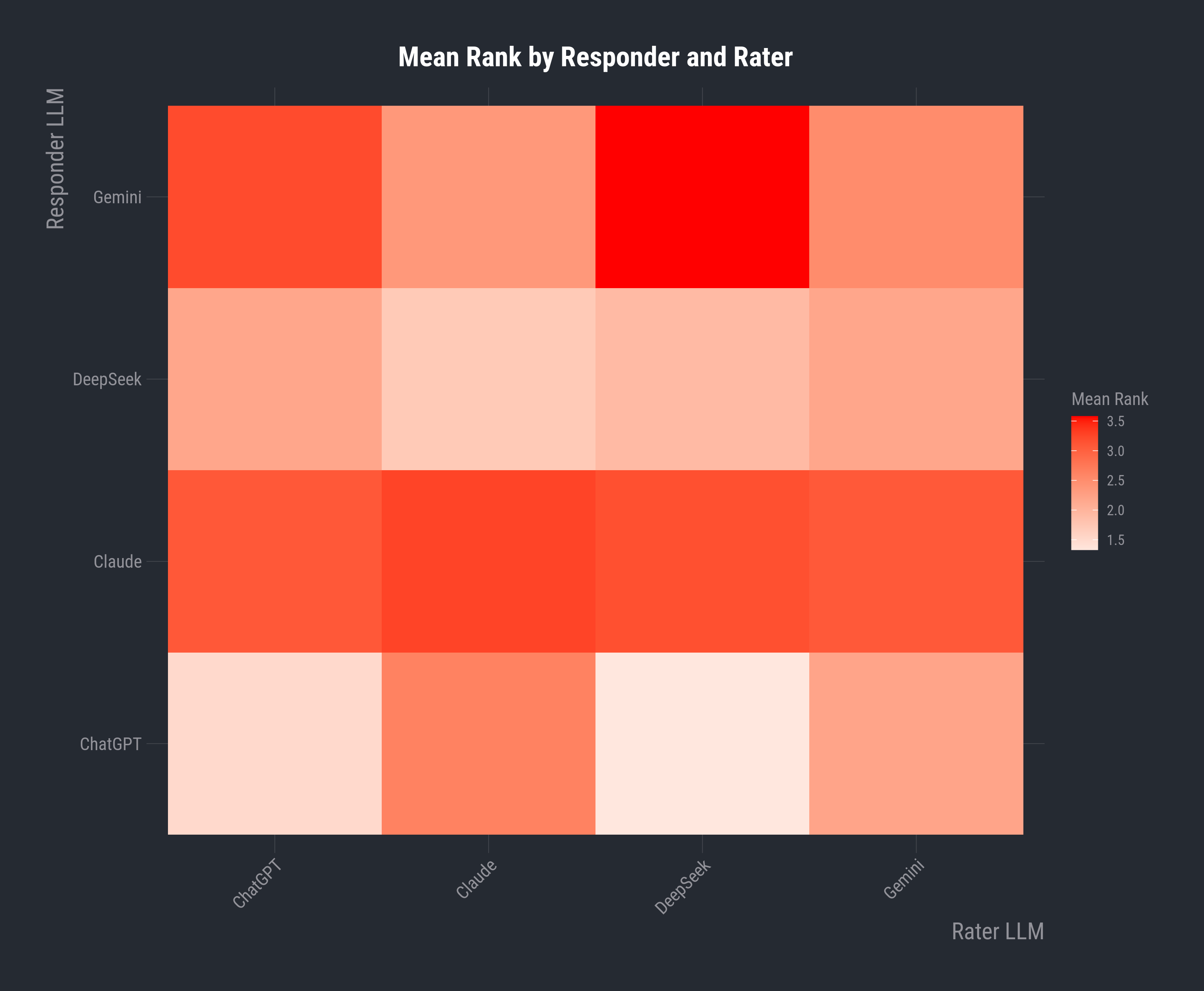
Finally, it’s worth remarking that there is a quite a lot of variability in these rankings, justifying the statistical approach, caused by the variation (statistical noise) in the underlying generation mechanism within these LLMs - even the original responses vary from one run to another. It is therefore a rarity that the rankings are the same across the independent runs. For example, on prompt 01, with Claude as both rater and responder, they place themselves in 4th place five times, in 3rd four times and, miraculously, in 1st place on just one occasion!
Note: for this study, the following models types were used:
- ChatGPT-4o (latest, at time of writing)
- Claude 3.7 Sonnet (v. 2025-02-19)
- DeepSeek chat
- Gemini 2.0 Flash
Study: ChatGPT vs Claude
In this mini study, we pit ChatGPT (4o-mini) against Claude (3.5 Sonnet). After running the prompts through the
preference pump, then aggregating results with bin/tally_preferences.py, the results are as follows:
bash ./bin/run_preference.sh "chatgpt claude"
Pumping prompt 00
Pumping prompt 01
Pumping prompt 02
Pumping prompt 03
Pumping prompt 04
Pumping prompt 05
Pumping prompt 06
Pumping prompt 07
Pumping prompt 08
Pumping prompt 09
python bin/tally_preferences.py
Results (raw):
| prompt_no | chatgpt | claude | disagree |
|------------:|:----------|:---------|:-----------|
| 00 | claude | claude | |
| 01 | claude | chatgpt | * |
| 02 | chatgpt | chatgpt | |
| 03 | chatgpt | claude | * |
| 04 | chatgpt | chatgpt | |
| 05 | chatgpt | claude | * |
| 06 | chatgpt | chatgpt | |
| 07 | chatgpt | chatgpt | |
| 08 | chatgpt | chatgpt | |
| 09 | chatgpt | chatgpt | |
Based on this table, it’s clear that both providers usually prefer ChatGPT’s answers, with Claude only choosing its own responses 3 / 10 times. If we discount potentially contentious results by excluding those where the models disagree, we find that Claude only picked its own work 1 / 7 times! (On the same reduced set, ChatGPT only picked Claude’s once.)
This finding is consistent with the study of four providers discussed in the previous section.
Some interesting things I found on reading the response analysis:
- On two occasions, Claude canned the response by suggesting “I cannot do that” more or less, whereas ChatGPT on the
contrary took the ball and ran with it.
- For example, on prompt 08, Claude said: “I can’t actually experience what it’s like to be a potato since I’m an AI”
- This lack of imagination was later marked down by both models, including itself of course.
- Claude praised ChatGPT for “engaging creatively … while remaining grounded in factual information” - pun intended? 🥔
- Claude raised good points on contested prompt 03, a short quiz on acronyms:
- It criticized ChatGPT for using two very similar acronyms within the same quiz: DNA and RNA.
- Claude also noticed that ChatGPT got “NASA” wrong (it said Agency instead of Administration for the second A).
References
-
https://www.reddit.com/r/ClaudeAI/comments/1jikxrc/claude_is_wonderful_but_can_make_mistakes/ ↩︎
-
Jiang, C., Xu, H. et al. (2024). Hallucination Augmented Contrastive Learning for Multimodal Large Language Model arXiv preprint ↩︎
-
Agrawal, A., Suzgun, M. et al. (2024). Do Language Models Know When They’re Hallucinating References? arXiv preprint ↩︎
-
https://analyticsindiamag.com/global-tech/anthropic-cracks-the-code-with-claude-3-7-sonnet/ ↩︎
-
Miserendino, S., Wang, M. et al. (2024). SWE-Lancer: Can Frontier LLMs Earn $1 Million from Real-World Freelance Software Engineering? arXiv preprint ↩︎